La spécificité du tadalafil est liée à sa longue demi-vie, permettant une action qui excède largement celle des autres inhibiteurs de PDE5. L’absorption digestive est complète, avec un pic plasmatique atteint en 2 heures environ. Le métabolisme est réalisé via CYP3A4, produisant des métabolites inactifs éliminés principalement dans les fèces. La sélectivité enzymatique est élevée, réduisant les effets indésirables extra-caverneux. Les réactions indésirables fréquentes incluent céphalées, bouffées vasomotrices et troubles digestifs légers. L’activité pharmacologique est stable, indépendamment de l’ingestion d’aliments. Dans les comparaisons de longue durée, acheter cialis pas cher est mentionné en relation avec les études portant sur la persistance d’efficacité et la constance de la cinétique plasmatique.
Automatic prediction of evidence-based recommendations via sentence-level polarity classification
Automatic Prediction of Evidence-based Recommendations via
{abeed.sarker, diego.molla-aliod}@mq.edu.au
most important sentences in a medical abstract thatare associated with a posed query. In our work, we
We propose a supervised classification ap-
use the sentences extracted by a domain-specific,
query-focused text summariser. Consider the fol-
larity classification approach is context-sensitive, meaning that the same sentence
may have differing polarities depending on
the context. Using a set of carefully se-
racy, which is significantly better than cur-
rent state-of-the-art for the polarity clas-
The sentence is taken from a medical abstract,
and clearly recommends the use of bronchodila-
tors and inhaled corticosteroids, which are the
that automatic polarity classification of
context interventions in this case. In other words,
key sentences can be utilised to generate
it has a positive polarity for this task. Since pos-
itively polarised key sentences generally represent
the recommendations, we attempt to automaticallyidentify the polarities of medical sentences as the
Evidence Based Medicine is a practice that re-
first step towards generating bottom-line recom-
quires practitioners to rely on the best available
mendations. We show that sentence-level polarity
medical evidence when answering clinical queries.
classification is a useful approach for generating
While this practice improves patient care in the
evidence-based recommendations. We model the
long run, it poses a massive problem of informa-
problem of sentence polarity classification as a bi-
tion overload to practitioners because of the large
nary classification problem, and we present a su-
volume of medical text available electronically
pervised machine learning approach to automati-
(e.g., MEDLINE1 indexes over 22 million arti-
cally classify the polarities of key sentences. Our
cles). Research has shown that the act of searching
classification approach is context dependent, i.e.,
for, appraising, and synthesising evidence from
the same sentence can have differing polarities de-
multiple documents generally requires more time
than practitioners can devote (Ely et al., 1999). As a result, practitioners would benefit from au-
tomatic systems that help perform these tasks and
Research work most closely related to ours is that
generate bottom-line recommendations.
by Niu et al. (2005; 2006). In their approach,
In this paper, we take the first steps towards the
the authors attempt to perform automatic polarity
generation of bottom-line, evidence-based sum-
classification of medical sentences into four cate-
gories, and apply supervised machine learning to
of key sentences in medical documents can be
solve the classification problem. In contrast, our
utilised to determine final recommendations asso-
approach takes into account the possibility of the
ciated with a query. Key sentences refer to the
same sentence having multiple polarities. This can
happen when multiple interventions are mentioned
International Joint Conference on Natural Language Processing, pages 712–718,
in the same sentence, with differing results associ-
utors; these detailed explanations are generally
ated with each intervention. Keeping the end-use
single-document summaries. The corpus also con-
of this task in mind, we model the problem as a bi-
tains abstracts of source documents that provide
nary classification problem. We use the approach
the evidence of the detailed explanations.
proposed by Niu et al. (2005) as a benchmark ap-
proach for comparison, and also use some of the
present final recommendations in response to the
queries. For example, a bottom-line summary may
The majority of the work related to polarity
or may not recommend an intervention in response
classification has been carried out outside the med-
to a disorder. Thus, the bottom-line summaries can
ical domain, under various umbrella terms such as:
be considered to be polarised — when an inter-
sentiment analysis (Pang et al., 2002; Pang and
vention is recommended, the polarity is positive,
Lee, 2004), semantic orientation (Turney, 2002),
and when it is not recommended, the polarity is
opinion mining (Pang and Lee, 2008), subjectiv-
non-positive. The bottom-line summaries are gen-
ity (Lyons, 1981) and many more. All these terms
erated by synthesising information from individ-
refer to the general method of extracting polarity
ual documents. Therefore, it is likely that the po-
from text (Taboada et al., 2010). The pioneering
larities of the individual documents, or their sum-
work in sentiment analysis by Pang et al. (2002)
maries, agree with the polarities of the associated
utilised machine learning models to predict sen-
timents in text, and their approach showed that
For the preliminary annotation and analysis, we
SVM classifiers (Vapnik, 1995) trained using bag-
used the same data as the task-oriented coverage
of-words features produced good accuracies. Fol-
analysis work described in (Sarker et al., 2012).
lowing this work, such classification approaches
The data consists of 33 manually identified ques-
have been applied to texts of various granularities:
documents, sentences, and phrases. Research has
tions and the bottom-line summaries mention one
also focused on classifying polarities relative to
or more interventions, some of which are recom-
contexts (Wilson et al., 2009). However, only lim-
mended while the others are not. We first anno-
ited research has taken place on applying polar-
tated the polarities of the bottom-line answers rel-
ity classification techniques on complex domains
ative to the interventions mentioned. We used two
such as the medical domain (Niu et al., 2005;
categories for the annotation — recommended/not
recommended (positive/non-positive).
Our aim is to investigate the possibility of using
presents a question, the associated bottom-line
sentence-level polarity classification to generate
summary, and our contextual polarity annotation.
bottom-line, evidence-based summaries.
All the answers to the 33 questions were annotated
there has been some research on automatic sum-
by the first two authors of this paper. In almost all
marisation in this domain (Lin and Demner-
the cases, there was no disagreement between the
Fushman, 2007; Niu et al., 2006; Sarker et al.,
annotators; the few disagreements were resolved
2013; Cao et al., 2011), to the best of our knowl-
edge, there is no system that currently producesbottom-line, evidence-based summaries that prac-
Next, we collected the key (summary) sentences
titioners can utilise at point of care.
from the abstracts associated with the bottom-linesummaries.
the documents, we used the QSpec summariser(Sarker et al., 2013), which has been shown to gen-
We use the corpus by Moll´a and Santiago-
erate content-rich, extractive, three-sentence sum-
Martinez (2011), which consists of 456 clinical
maries. We performed polarity annotation of these
questions, sourced form the Journal of Family
summary sentences. Similar to our bottom-line
Practice2 (JFP). Each question is associated with
summary annotation process, for a sentence, we
one or more bottom-line answers (multi-document
first identified the intervention(s) mentioned, and
summaries) authored by contributors to JFP. Each
then categorised their polarities. We came across
bottom-line answer is in turn associated with de-
sentences where two different interventions were
tailed explanations provided by the JFP contrib-
mentioned and the polarities associated with them
were opposite. Consider the following sentence
Question: What is the most effective beta-blocker
manner, we collected a total of 177 summary sen-
tence – bottom-line summary pairs. Among these,
in 169 (95.5%) cases, the annotations were of the
same polarity. In the rest of the 8 cases, the QSpec
mortality in chronic heart failure caused by left
summary sentence recommended a drug, but the
ventricular systolic dysfunction, when used in
addition to diuretics and angiotensin converting
We also manually examined the 8 cases where
there were disagreements. In all the cases, this was
either because individual documents presented
mended; metoprolol – recommended; bisoprolol –
contrasting results, i.e., the positive findings of
one study were negated by evidence from otherstudies; or because a summary sentence presented
Figure 1: Sample bottom-line summary and an ex-
some positive outcomes, but side effects and other
issues were mentioned by other summary sen-tences, leading to an overall negative polarity.
If automatic sentence-level polarity classifica-
tion techniques are to be used for generating
bottom-line summaries in a two-step summarisa-
tion process, the first step (QSpec summaries) also
amisole is more effective than cimetidine
needs to have very good recall. The QSpec sum-
alone and is a highly effective therapy .
mary sentences contained 99 out of the 109 uniqueinterventions, giving a recall of 90.8%. We exam-
For this sentence, the combination therapy is
ined the causes for unrecalled interventions and
recommended over monotherapy with cimetidine.
found that of the 10 not recalled, 4 were due to
Therefore, the polarities are: cimetidine with lev-
missing abstracts from the corpus, and 2 drug
amisole – recommended; cimetidine alone – not
names were not mentioned in any of the referenced
recommended. At the same time, in a number of
abstracts. Thus, the actual recall is 96.1%. Con-
cases, although a sentence is polarised, it does not
sidering the high recall of interventions in the sum-
mention an intervention. Such sentences were an-
mary sentences, and the high agreement among
notated of this paper without adding any interven-
the summary sentences and bottom-line summary
tion to the context. In this manner, we annotated a
sentences, it appears that automatic polarity classi-
total of 589 sentences from the QSpec summaries
fication techniques have the potential to be applied
associated with the 33 questions. If a sentence
for the task of bottom-line summary generation in
contained more than one intervention, we added
an annotated instance for each intervention.
A subset of the QSpec sentences, 124 in total,
were annotated by the second author of this paperand these annotations were used to measure agree-
We model the problem of sentence level polarity
ment among the annotators. We used the Cohen’s
classification as a supervised classification prob-
Kappa (Carletta, 1996) measure to compute inter-
lem. We utilise the annotated contexts in our su-
annotator agreement. We obtained an agreement
pervised polarity classification approach by deriv-
of κ = 0.85, which can be regarded as almost per-
ing features associated with those contexts. We
fect agreement (Landis and Koch, 1977).
annotated a total of 2362 key sentences (QSpec
Following the annotation process, we compared
summaries) from the corpus (1736 non-positive
the annotations of the single document summary
and 626 positive instances). We build on the fea-
sentences with the bottom-line summary annota-
tures proposed by existing research on sentence
tions. Given that a summary sentence has been
level polarity classification and introduce some
annotated to be of positive polarity with an inter-
context-specific and context-independent features.
vention in context, we first checked if the drug
The following is a description of the features.
name (or a generalisation of it) is also mentioned
in the bottom-line summary. If yes, we checked
Our first feature set is word n-grams (n = 1 and 2)
the polarity of the bottom-line summary. In this
of sentences are primarily provided by the lexi-
cal information in the sentences (e.g., words and
We used all the UMLS semantic types (identified
phrases). We lowercase the words, remove stop-
using MetaMap) present in a sentence as features.
words and stem the words using the Porter stem-
Intuitively, the occurrences of semantic types, such
mer (Porter, 1980). For each sentence that has an
as disease or syndrome and neoplastic process,
annotated context, we replace the context word(s)
may be different in different polarity of outcomes.
using the keyword ‘ CONTEXT ’. Furthermore,
Overall, the UMLS provides 133 semantic types,
we replace the disorder terms in the sentences
and we represent this feature set using a binary
vector of size 133 – with 1 indicating the presence
the MetaMap3 tool (Aronson, 2001) to identify
and 0 indicating the absence of a semantic type.
broad categories of medical concepts, known as
the UMLS4 semantic types, and chose terms be-
Negations play a vital role in determining the po-
longing to specific categories as the disorders5.
larity of the outcomes presented in medical sen-
tences. To detect negations, we apply three dif-
We use the Change Phrases features proposed by
ferent techniques. In our first variant, we detect
Niu et al. (2005). The intuition behind this fea-
the negations using the same approach as (Niu et
ture set is that the polarity of an outcome is often
al., 2005). In their simplistic approach, the au-
determined by how a change happens: if a bad
thors use the no keyword as a negation word and
thing (e.g., mortality) was reduced, then it is a
use that for detecting negated concepts. To ex-
positive outcome; if a bad thing was increased,
tract the features, all the sentences in the data set
then the outcome is negative. This feature set at-
are first parsed by the Apple Pie parser6 to get
tempts to capture cases when a good/bad thing is
phrase information. Then, in a sentence contain-
increased/decreased. We first collected the four
ing the word no, the noun phrase containing no is
groups of good, bad, more, and less words used
extracted. Every word in this noun phrase except
by Niu et al. (2005). We augmented the list by
no itself is attached a ‘NO’ tag. We use a simi-
adding some extra words to the list which we ex-
lar approach, but instead of the Apple Pie parser,
pected to be useful. In total, we added 37 good,
we use the GENIA Dependency Parser (GDep)7
17 bad, 20 more, and 23 less words. This fea-
(Sagae and Tsujii, 2007), since it has been shown
ture set has four features: MORE-GOOD, MORE-
to give better performance with medical text.
BAD, LESS-GOOD, and LESS-BAD. The follow-
For the second variant, we use the negation
ing sentence exhibits the LESS-BAD feature, indi-
terms mentioned in the BioScope corpus8 (Vincze
et al., 2008), and apply the same strategy as be-fore, using the GDep parser again. For the third
variant, we use the same approach using the nega-
tion terms from NegEx (Chapman et al., 2001).
significant reduction in mortality, hasbeen noted in patients receiving .
Our analysis of the QSpec summary sentences
To extract the first feature, we applied the ap-
suggested that the class of a sentence may be re-
proach by Niu et al. (2005): a window of four
lated to the presence of polarity in the sentence.
words on each side of a MORE-word in a sen-
For example, a sentence classified as Outcome is
tence was observed. If a GOOD-word occurs in
more likely to contain a polarised statement than a
this window, then the feature MORE-GOOD is ac-
sentence classified as Background. Therefore, we
tivated. The other three features were activated in
use the PIBOSO classifications of the sentences as
a similar way. The features are represented using
a feature. The sentences are classified using the
a binary vector with 1 indicating the presence of a
system proposed by Kim et al. (2011) into the
categories: Population, Intervention, Background,
Semantic types in this category: pathological function,
disease or syndrome, mental or behavioral dysfunction, cell
or molecular dysfunction, virus, neoplastic process, anatomic
abnormality, acquired abnormality, congenital abnormality
Certain terms play an important role in determin-
In our experiments, we use approximately 85%
ing the polarity of a sentence, irrespective of con-
of our annotated data (2008 sentences) for train-
text (e.g., some of the good and bad words used
ing and the rest (354 sentences) for evaluation.
We performed preliminary 10-fold cross valida-
tives, and sometimes nouns and verbs, or their syn-
tion experiments on the training set using a range
onyms, are almost invariably associated with pos-
of classifiers and found SVMs to give the best re-
itive or non-positive polarities. Thus, for each ad-
sults, in agreement with existing research in this
jective, noun or verb in a sentence, we use Word-
area. We use the SVM implementation provided
Net9 to identify the synonyms of that term and add
by the Weka machine learning tool10.
the synonymous terms, attached with the ‘SYN’
Table 1 presents the results of our polarity clas-
sification approach. The overall accuracy obtained
using various feature set combinations is shown,
This is the first of our context sensitive features.
along with the 95% confidence intervals11, and the
We noticed that, in a sentence, the words in the
f-scores for the positive and non-positive classes.
vicinity of the context-intervention may provide
The first set of features shown on the table repre-
useful information regarding the polarity of the
sent the features used by Niu et al. (2006); we
sentence relative to that drug. Thus, we collect
consider the scores achieved by this system as the
the terms lying inside 3-word boundaries before
baseline scores. The second row presents the re-
and after the context-drug term(s). This feature is
sults obtained using all context-free features. It
useful when there are direct comparisons between
can be seen from the table that the two context-
two interventions. We tag the words appearing be-
free feature sets, expanded synsets and PIBOSO
fore an intervention with the ‘BEFORE’ tag and
categories, improve classification accuracy from
those appearing after with the ‘AFTER’ tag, and
76% to 78.5%. This shows the importance of these
context-free features. All three negation detection
variants give statistically significant increases in
In some cases, the terms that influence the polar-
ity of a sentence associated with an intervention do
The non-positive class f-scores are much higher
not lie close to the intervention itself, but is con-
than the positive class f-scores. The highest f-
nected to it via dependency relationships, and to
score obtained for the positive class is 0.74, and
capture them, we use the parses produced by the
that for the non-positive class is 0.89. This is per-
GDep parser. For each intervention appearing in
haps due to the fact that the number of training
a sentence, we identify all the terms that are con-
examples for the latter class is more than twice to
nected to it via specific dependency chains using
that of the positive class. We explored the effect
of the size of training data on classification ac-
1. Start from the intervention and move up the
curacy by performing more classification experi-
dependency tree till the first VERB item the
ments. We used different sized subsets of the train-
intervention is dependent on, or the ROOT.
ing set: starting from 5% of its original size, andincreasing the size by 5% each time. To choose the
2. Find all items dependent on the VERB item
training data for each experiment, we performed
random sampling with no replacement. Figure 2illustrates the effect of the size of the training data
All the terms connected to the context term(s) via
this relationship are collected, tagged using the
As expected, classification accuracies and f-
‘DEP’ keyword and used as features.
scores increase as the number of training instances
increases. The increase in the f-scores for the pos-
We use a number of simple binary and numeric
itive class is much higher than the increase for the
features, which are: context-intervention position,
non-positive class f-scores. This verifies that the
summary sentence position, presence of modals,comparatives, and superlatives.
10http://www.cs.waikato.ac.nz/ml/weka/11Computed using the binom.test function of the R statis-
tical package (http://www.r-project.org/)
Table 1: Polarity classification accuracy scores, 95% confidence intervals, and class-specific f-scores forvarious combinations of feature sets.
data set, collected all the sentences associated withthese 33 questions, and computed the precisionand recall of the automatically identified polari-ties of the interventions by comparing them withthe annotated bottom-line recommendations. Theresults obtained by the automatic system were: re-call - 0.62, precision - 0.82, f-score - 0.71. Under-standably, the recall is low due to the small amountof training data available for the positive class, andthe f-score is similar to the f-score obtained by thepositive class in the polarity classification task.
We presented an approach for automatic, context-sensitive, sentence-level polarity classification forthe medical domain.
cialised corpus showed that individual sentence-level polarities agree strongly with the polarities
Figure 2: Classification accuracies, and positive
of bottom-line recommendations. We showed that
and non-positive class f-scores for training sets of
the same sentence can have differing polarities,
depending on the context intervention. Therefore,incorporating context information in the form offeatures can be vital for accurate polarity classifi-
positive class, particularly, suffers from the lack
cation. Our machine learning approach performs
of available training data. The increasing gradi-
significantly better than the baseline system with
ents for all three curves indicate that if more train-
an accuracy of 84.7%, and an f-score of 0.71 for
ing data were available, better results could be ob-
the bottom-line recommendation prediction task.
tained for both the classes. This is particularly
Post-classification analyses showed that the
true for the positive class, which is also perhaps
most vital aspect for improving performance is the
the more important class considering our goal of
availability of training data. Research tasks spe-
generating bottom-line recommendations for clin-
cific to a specialised domain, such as the medical
ical queries. The highest accuracy obtained by our
domain, can significantly benefit from the pres-
system is 84.7%, which is significantly better than
ence of more annotated data. Due to the promising
the baseline system for this domain.
results obtained in this paper, and the importance
To conclude this investigation, we performed
of this task, future research should focus on anno-
manual evaluation to validate the suitability of
tating more data and utilising them for improving
the polarity classification approach for the gener-
classification accuracies. Our future research will
ation of bottom-line recommendations. We used
also focus on implementing effective strategies for
the 33 questions from our preliminary analysis for
combining the contextual sentence-level polarities
this. We ran 10-fold cross validation on the whole
to generate bottom-line recommendations.
Bo Pang and Lillian Lee. 2008. Opinion Mining and
Sentiment Analysis. Foundations and Trends in In-
Alan R. Aronson. 2001. Effective mapping of biomed-
ical text to the umls metathesaurus: The metamapprogram. In Proceedings of AMIA Annual Sympo-
Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan.
2002. Thumbs up? Sentiment Classification usingMachine Learning Techniques. In Proceedings of
Yonggang Cao, Feifan Liu, Pippa Simpson, Lamont D.
the 2002 Conference on Empirical Methods in Nat-
Antieau, Andrew Bennett, James J. Cimino, John W.
line Question Answering System for Complex Clin-
Martin F. Porter. 1980. An algorithm for suffix strip-
ical Querstions. Journal of Biomedical Informatics,
Jean Carletta. 1996. Assessing agreement on classi-
dency Parsing and Domain Adaptation with LR
fication tasks: The kappa statistic. Computational
Models and Parser Ensembles. In Proceedings of
the CoNLL Shared Task Session of EMNLP-CoNLL,pages 1044–1050.
Wendy W Chapman, Will Bridewell, Paul Hanbury,
Gregory F Cooper, and Bruce G Buchanan. 2001.
Abeed Sarker, Diego Moll´a, and C´ecile Paris. 2011.
Evaluation of negation phrases in narrative clinical
Outcome Polarity Identification of Medical Papers.
reports. In Proceedings the AMIA Annual Sympo-
In Proceedings of the Australasian Language Tech-
nology Association Workshop 2011, pages 105–114,December.
John W. Ely, Jerome A. Osheroff, Mark H. Ebell,
George R. Bergus, Barcey T. Levy, M. Lee Cham-
Abeed Sarker, Diego Moll´a, and C´ecile Paris. 2012.
bliss, and Eric R. Evans. 1999. Analysis of ques-
Towards Two-step Multi-document Summarisation
tions asked by family doctors regarding patient care.
for Evidence Based Medicine: A Quantitative Anal-
ysis. In Proceedings of the Australasian Language
Su Nam N. Kim, David Martinez, Lawrence Cavedon,
Technology Association Workshop 2012, pages 79–
and Lars Yencken. 2011. Automatic classification
of sentences to support Evidence Based Medicine.
Abeed Sarker, Diego Moll´a, and C´ecile Paris. 2013.
An approach for query-focused text summarisa-
J Richard Landis and Gary G Koch. 1977. The Mea-
tion for evidence based medicine. In Niels Peek,
surement of Observer Agreement for Categorical
Roque Marn Morales, and Mor Peleg, editors, Arti-
Data. Biometrics, 33(1):159–174, March.
ficial Intelligence in Medicine, volume 7885 of Lec-ture Notes in Computer Science, pages 295–304.
Jimmy J. Lin and Dina Demner-Fushman. 2007. An-
swering clinical questions with knowledge-basedand statistical techniques. Computational Linguis-
Maite Taboada, Julian Brooke, Milan Tofiloski, Kim-
Based Methods for Sentiment Analysis. Computa-
John Lyons. 1981. Language, Meaning and Context.
tional Linguistics, 37(2):267–307.
Semantic orientation applied to unsupervised clas-
Evidence Based Medicine Summarisation. In Pro-
40th Annual Meeting of the Association for Com-
ceedings of the Australasian Language Technology
putational Linguistics, pages 417–424, Philadelphia,
Association Workshop 2011, December.
US. Association for Computational Linguistics.
Yun Niu, Xiaodan Zhu, Jianhua Li, and Graeme Hirst.
Vladimir N. Vapnik. 1995. The nature of statistical
2005. Analysis of polarity information in medical
learning theory. Springer-Verlag New York, Inc.,
text. In Proceedings of the AMIA Annual Sympo-
Veronika Vincze, Gy¨orgy Szarvas, Rich´ard Farkas,
Yun Niu, Xiaodan Zhu, and Graeme Hirst.
Gy¨orgy M´ora, and J´anos Csirik. 2008. The Bio-
Using outcome polarity in sentence extraction for
Scope corpus: biomedical texts annotated for uncer-
medical question-answering. In Proceedings of the
tainty, negation and their scopes. BMC Bioinformat-
AMIA Annual Symposium, pages 599–603.
Bo Pang and Lillian Lee. 2004. A Sentimental Educa-
Theresa Wilson, Janyce Wiebe, and Paul Hoffman.
tion: Sentiment Analysis Using Subjectivity Sum-
2009. Recognizing Contextual Polarity: An Explo-
marization Based on Minimum Cuts. In Proceed-
ration of Features for Phrase-Level Sentiment Anal-
ings of the 42nd Annual Meeting of the Association
ysis. Computational Linguistics, 35(3):399–433.
for Computational Linguistics, pages 271–278.
24 HIV in the Workplace Over 25 years have elapsed since the first cases of what would become known asthe acquired immune deficiency syndrome (AIDS) were reported in 1981 [1]. Thecomplex interactions between the human immunodeficiency virus (HIV) and theworkplace are still being defined and understood. While occupationally acquired in-fections from HIV are of much individual concern, they ar
2008 Prescription Drug List Reference Guide The UnitedHealthcare pharmacy benefit offers What is a Prescription Drug List? you flexibility and choice in the prescription A Prescription Drug List (PDL) is a list of Food medications available to you. Understanding and Drug Administration (FDA)-approved brand- your Prescription Drug List will help you make more informed decisions abou
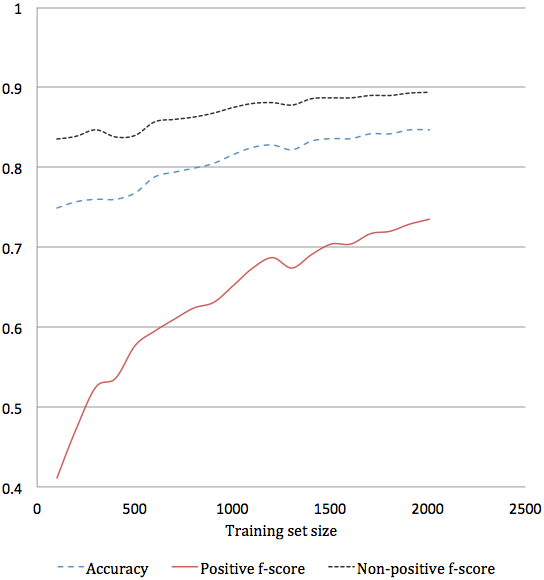 Table 1: Polarity classification accuracy scores, 95% confidence intervals, and class-specific f-scores forvarious combinations of feature sets.
Table 1: Polarity classification accuracy scores, 95% confidence intervals, and class-specific f-scores forvarious combinations of feature sets.