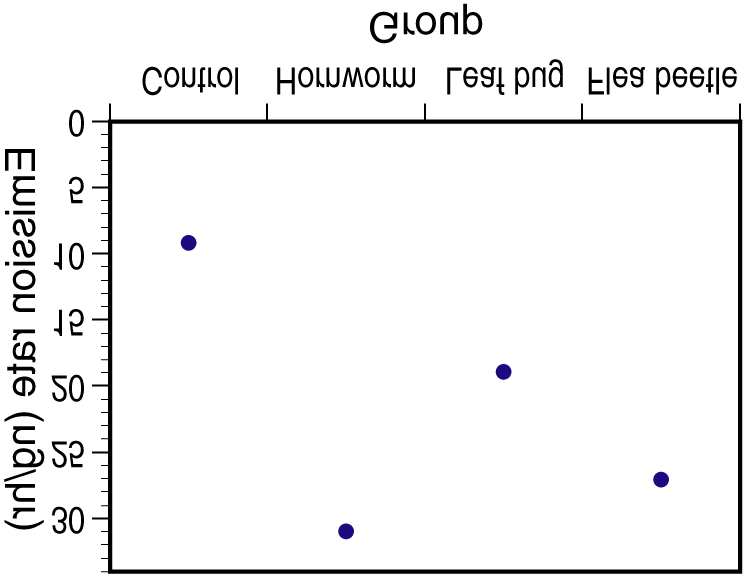
 Chapter 22 One-Way Analysis of Variance: Comparing Several Means
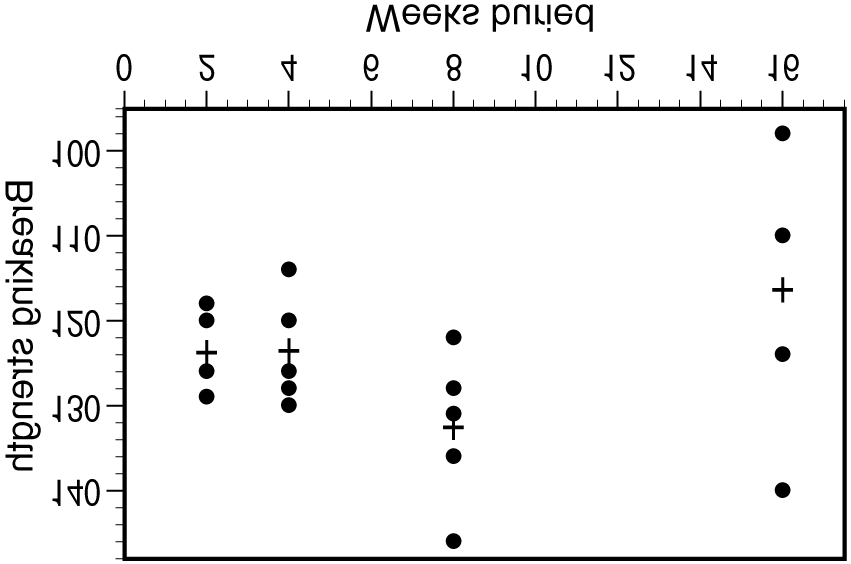
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5,
Chapter 22 One-Way Analysis of Variance: Comparing Several Means
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5, Golf.xls
VISA ASIA PACIFIC INFINITE GOLF PROGRAM 2010ENJOY LOW GREEN FEES AND EXCLUSIVE ACCESS AROUND THE WORLDRemarkably low green fees at 14 clubs in 7 countries. Access to 200 clubs in 46 countries. That's the privilege you enjoy as a CIMB or Direct Access Visa Infinite cardmember. Shanghai International Golf & Country ClubFor booking, please contact Visa Infinite customer Centre at 1800 803 006